The Random Forest analysis techniques was used to improve prediction on the German Credit Dataset.
The dataset is found:
url="http://freakonometrics.free.fr/german_credit.csv"
credit=read.csv(url, header = TRUE, sep = ",")str(credit)## 'data.frame': 1000 obs. of 21 variables:
## $ Creditability : int 1 1 1 1 1 1 1 1 1 1 ...
## $ Account.Balance : int 1 1 2 1 1 1 1 1 4 2 ...
## $ Duration.of.Credit..month. : int 18 9 12 12 12 10 8 6 18 24 ...
## $ Payment.Status.of.Previous.Credit: int 4 4 2 4 4 4 4 4 4 2 ...
## $ Purpose : int 2 0 9 0 0 0 0 0 3 3 ...
## $ Credit.Amount : int 1049 2799 841 2122 2171 2241 3398 1361 1098 3758 ...
## $ Value.Savings.Stocks : int 1 1 2 1 1 1 1 1 1 3 ...
## $ Length.of.current.employment : int 2 3 4 3 3 2 4 2 1 1 ...
## $ Instalment.per.cent : int 4 2 2 3 4 1 1 2 4 1 ...
## $ Sex...Marital.Status : int 2 3 2 3 3 3 3 3 2 2 ...
## $ Guarantors : int 1 1 1 1 1 1 1 1 1 1 ...
## $ Duration.in.Current.address : int 4 2 4 2 4 3 4 4 4 4 ...
## $ Most.valuable.available.asset : int 2 1 1 1 2 1 1 1 3 4 ...
## $ Age..years. : int 21 36 23 39 38 48 39 40 65 23 ...
## $ Concurrent.Credits : int 3 3 3 3 1 3 3 3 3 3 ...
## $ Type.of.apartment : int 1 1 1 1 2 1 2 2 2 1 ...
## $ No.of.Credits.at.this.Bank : int 1 2 1 2 2 2 2 1 2 1 ...
## $ Occupation : int 3 3 2 2 2 2 2 2 1 1 ...
## $ No.of.dependents : int 1 2 1 2 1 2 1 2 1 1 ...
## $ Telephone : int 1 1 1 1 1 1 1 1 1 1 ...
## $ Foreign.Worker : int 1 1 1 2 2 2 2 2 1 1 ...convert categorical variables as factors,
F=c(1,2,4,5,7,8,9,10,11,12,13,15,16,17,18,19,20)
for(i in F) credit[,i]=as.factor(credit[,i])create our training/calibration and validation/testing datasets, with proportion 1/3-2/3
i_test=sample(1:nrow(credit),size=333)
i_calibration=(1:nrow(credit))[-i_test]LogisticModel <- glm(Creditability ~ Account.Balance + Payment.Status.of.Previous.Credit + Purpose +
Length.of.current.employment +
Sex...Marital.Status, family=binomial,
data = credit[i_calibration,])fitLog <- predict(LogisticModel,type="response", newdata=credit[i_test,])library(ROCR)## Warning: package 'ROCR' was built under R version 3.3.3## Loading required package: gplots##
## Attaching package: 'gplots'## The following object is masked from 'package:stats':
##
## lowess## Loading required package: methodspred = prediction( fitLog, credit$Creditability[i_test])
perf <- performance(pred, "tpr", "fpr")
plot(perf)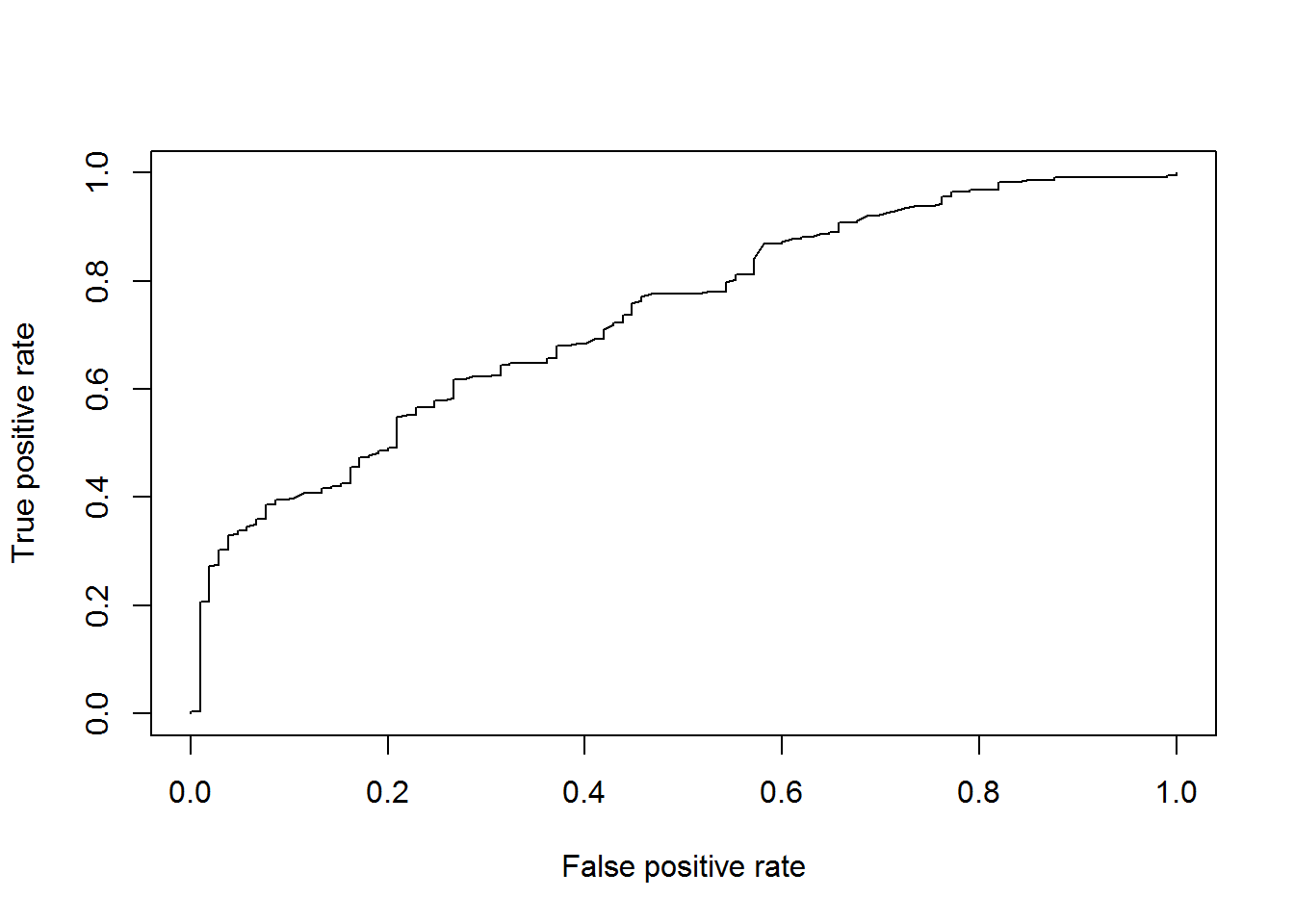
AUCLog1=performance(pred, measure = "auc")@y.values[[1]]
cat("AUC: ",AUCLog1,"n")## AUC: 0.7340226 nAlternative is to consider a logistic regression on all explanatory variables
LogisticModel <- glm(Creditability ~ ., family=binomial, data = credit[i_calibration,])
fitLog <- predict(LogisticModel,type="response",newdata=credit[i_test,])
pred = prediction( fitLog, credit$Creditability[i_test])
perf <- performance(pred, "tpr", "fpr")
plot(perf)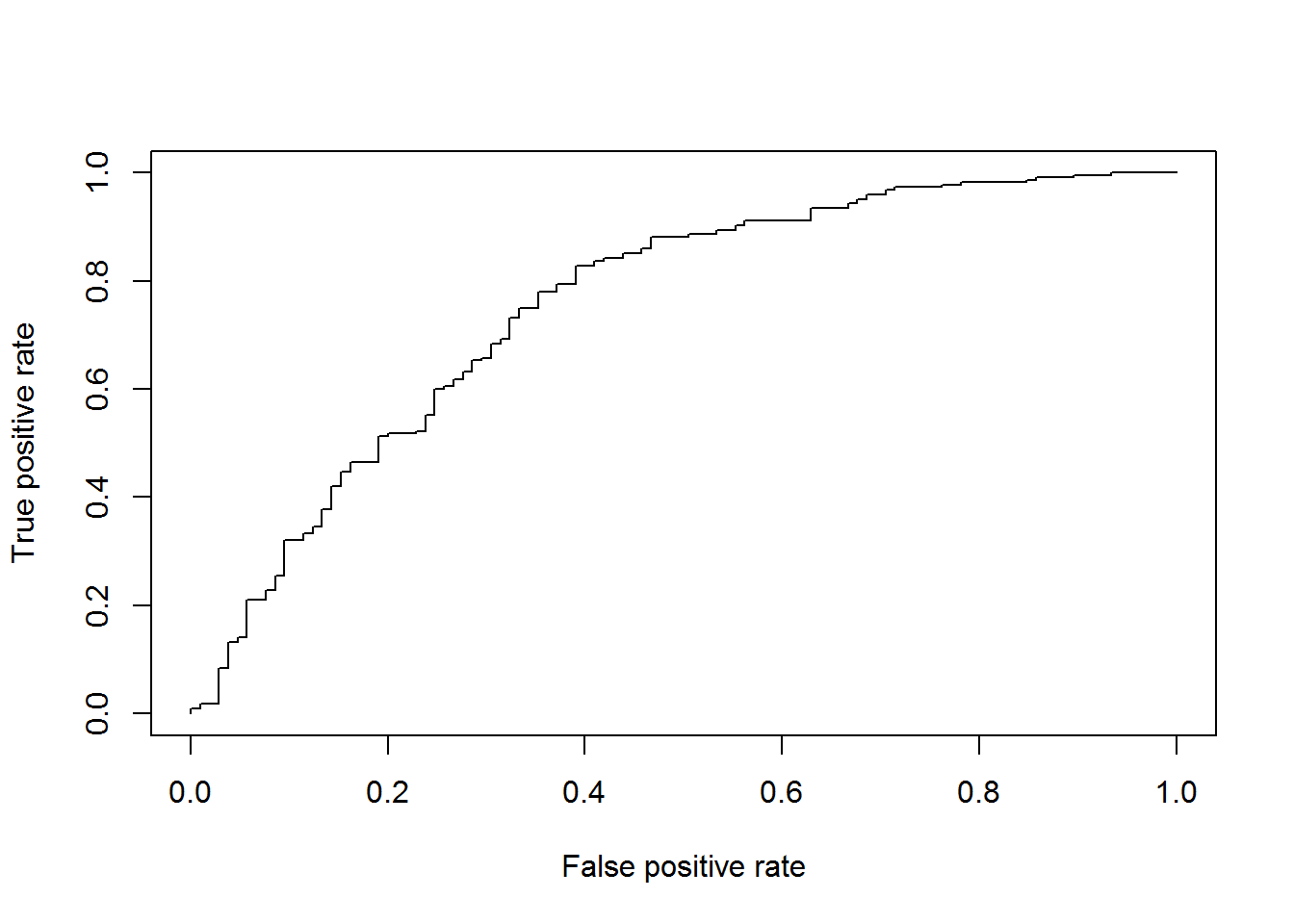
AUCLog2=performance(pred, measure = "auc")@y.values[[1]]
cat("AUC: ",AUCLog2,"n")## AUC: 0.7532581 nRegression tree method
library(rpart)
ArbreModel <- rpart(Creditability ~ ., data = credit[i_calibration,])library(rpart.plot)## Warning: package 'rpart.plot' was built under R version 3.3.3prp(ArbreModel,type=2,extra=1)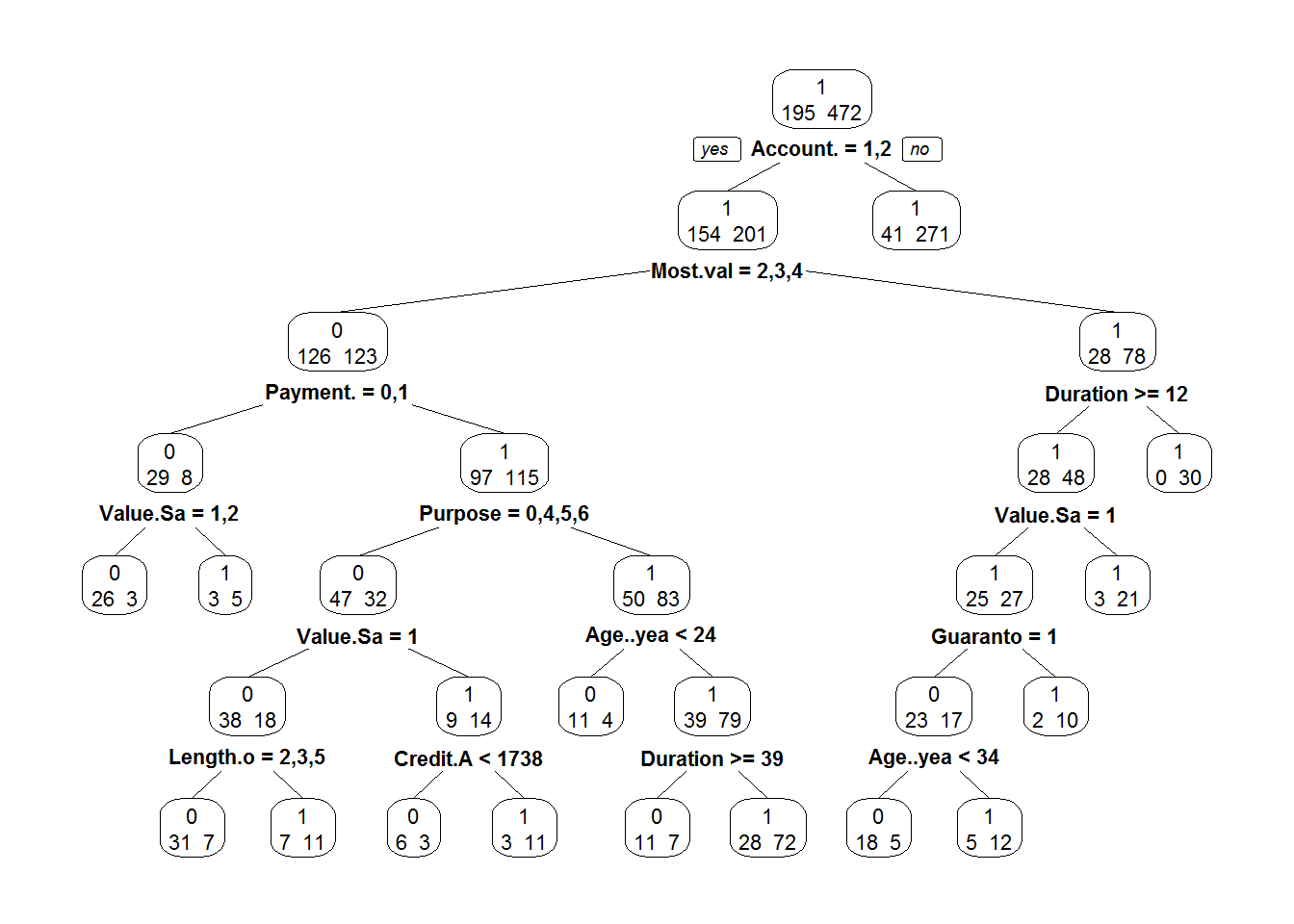
fitArbre <- predict(ArbreModel, newdata=credit[i_test,],type="prob")[,2]
pred = prediction( fitArbre, credit$Creditability[i_test])
perf <- performance(pred, "tpr", "fpr")
plot(perf)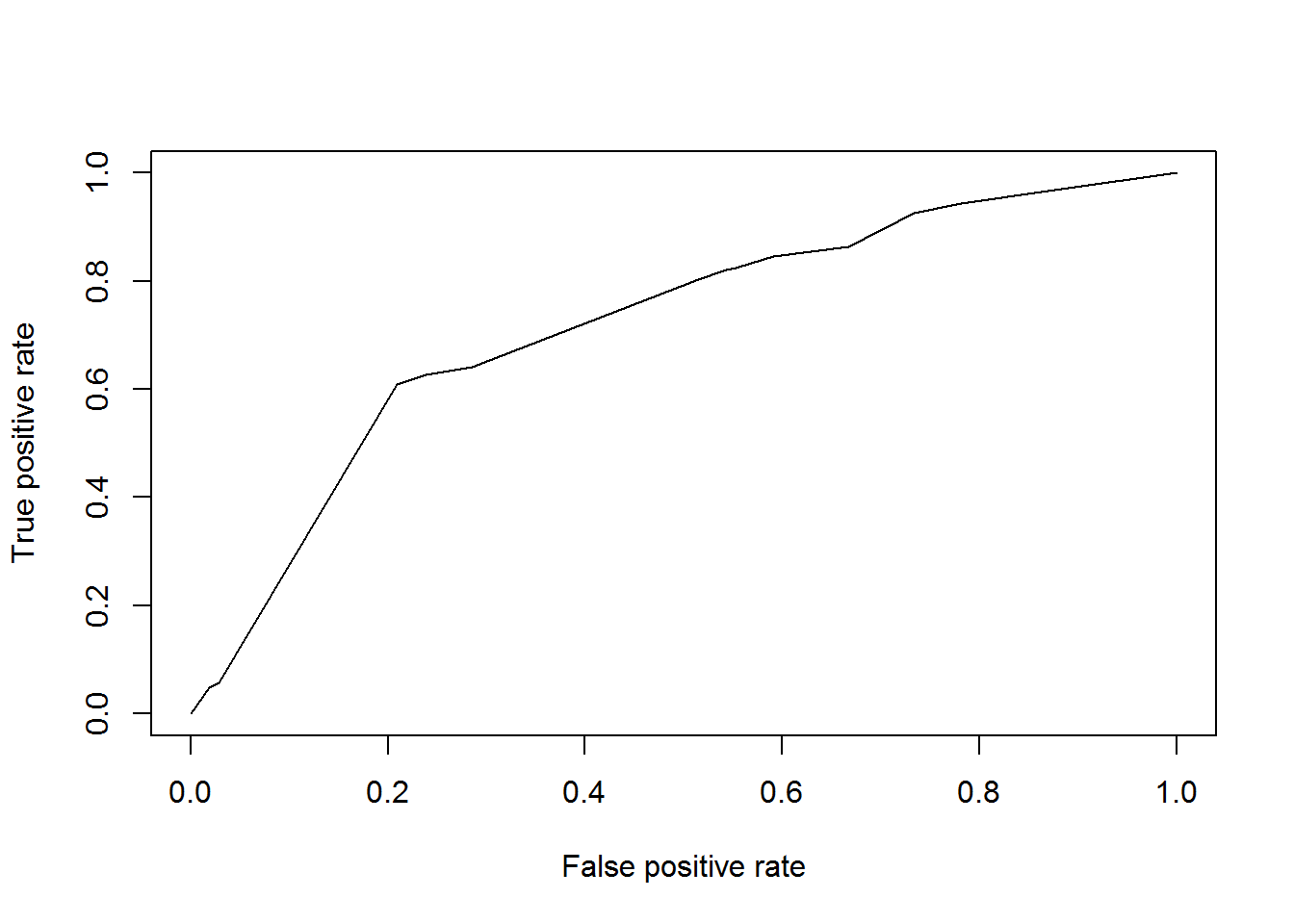
AUCArbre=performance(pred, measure = "auc")@y.values[[1]]
cat("AUC: ",AUCArbre,"n")## AUC: 0.719152 nRandom Forest analysis
library(randomForest)## Warning: package 'randomForest' was built under R version 3.3.3## randomForest 4.6-12## Type rfNews() to see new features/changes/bug fixes.RF <- randomForest(Creditability ~ .,data = credit[i_calibration,])
fitForet <- predict(RF,newdata=credit[i_test,],type="prob")[,2]
pred = prediction( fitForet, credit$Creditability[i_test])
perf <- performance(pred, "tpr", "fpr")
plot(perf)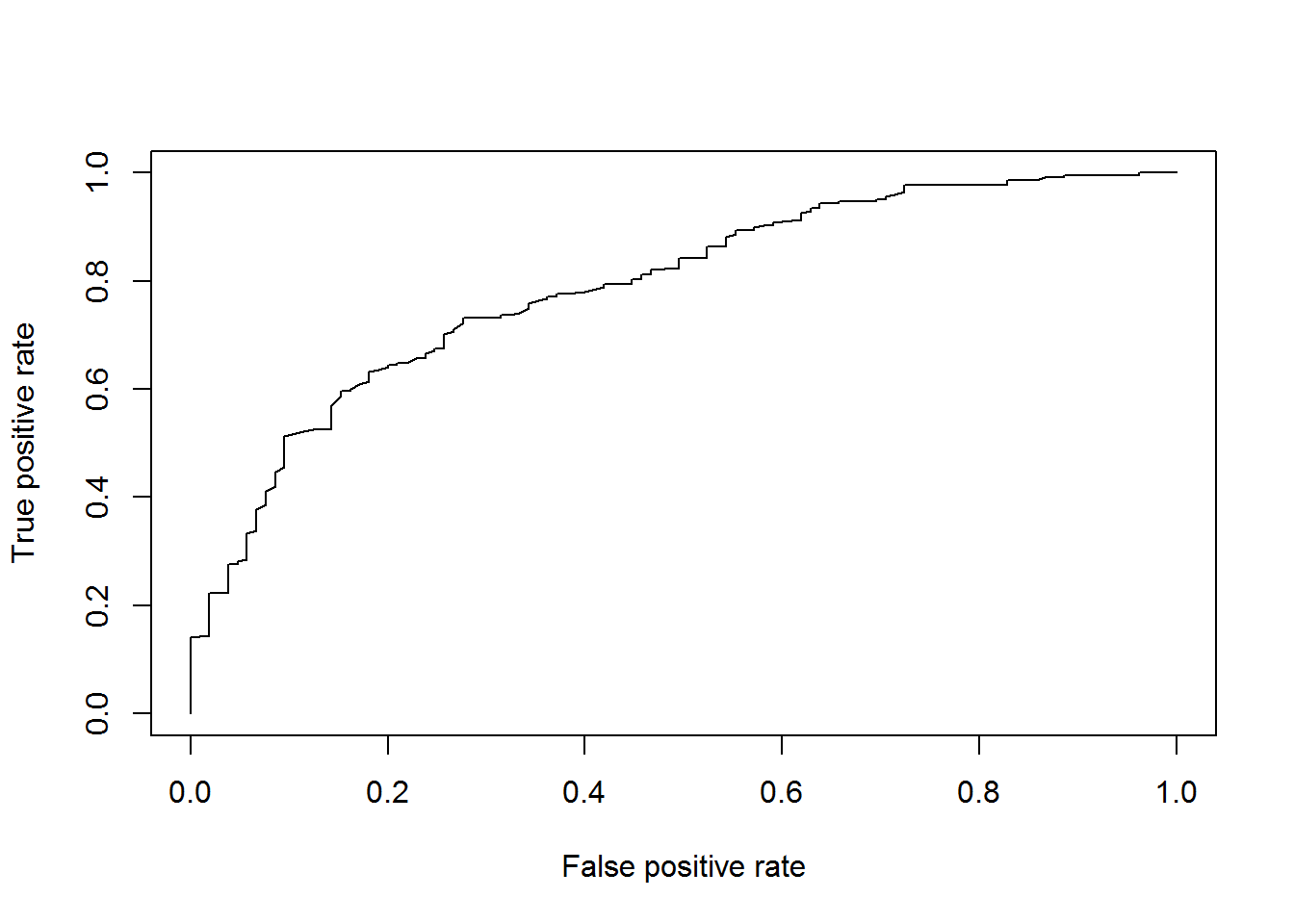
AUCRF=performance(pred, measure = "auc")@y.values[[1]]
cat("AUC: ",AUCRF,"n")## AUC: 0.7892439 n
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email